오늘은 NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE을 공부해보겠습니당!🤓
Introduction
Neural machine translation은 machine translation분야에서 새로 발견된 방법입니다. 그래서 하나의, 커다란 신경망을 설계하고 학습시킴으로써 올바른 번역을 하도록 합니다. 보통 이러한 신경망을 통한 기계번역엔 인코더와 디코더로 구성이 됩니다. 인코더 신경망(encoder nerual network)는 source sentence(번역해야 하는 문장)을 고정된 크기의 벡터로 인코딩해 줍니다. 디코더 신경망은 인코딩된 벡터로부터 번역을 하게 됩니다. 그다음, encoder-decoder system을 통해서 올바른 번역일 확률을 최대화 시키도록 학습시켜 줍니다.
이 인코딩의 역할을 신경망이 해줄 수 있는데 그렇게 되면 길이가 긴 문장은 해석하기가 어렵습니다. 그래서 이 논문에서는 align과 translate을 함께 해줄 수 있는 encoder-decoder model의 더 나은 버전을 제안합니다.
Each time the proposed model generates a word in a translation, it (soft-)searchs for a set of positions in a source sentence where the most relevant information is concetrated.
source sentence에서 관련있는 정보가 몰려있는 부분을 나타내는 context vector를 가지고 target word를 예측해줍니다. 그리고 인풋으로 들어가는 문장 전체를 단일 고정길이의 벡터로 바꿔주는 것이 아니라 adaptive하게 벡터의 부분집합만을 선택해주고 그것을 가지고 번역을 해줍니다.
Background
확률적인 관점에서 '번역'이란 무엇을 의미하는 것일까요?
translation is equivalent to finding a target sentence y that maximizes the conditional probability of y given a source sentence x, i.e. arg maxy p(y | x).
일단 conditional distribution이 번역 모델에 의해서 학습되면, source sentence가 주어졌을 때, conditional probability를 극대화시키는 문장을 찾아줍니다. 최근에 신경망을 통해서 conditional distribution을 찾는 모델이 제안되고 있는데, 이를 위해서 총 2가지의 RNN모델을 사용합니다. 위에서 얘기한 것처럼 하나는 encoder역할을, 다른 하나는 decoder역할을 해줍니다. 근래에 나온 접근법임에도 매우 유망한 결과를 보여주고 있습니다.
2.1 RNN Encoder-Decoder
-
먼저 인코더가 x=(x1,···,xTx)를 vector c로 읽어 들입니다.
- ht = f (xt, ht−1)(여기서 f는 LSTM을 사용)
- c = q({h1,··· ,hTx})(q({h1,··· ,hT})=hT)
-
여기서 ht는 시간 t일 때 hidden state를 의미하고, c는 hidden state의 sequence로부터 만들어진 벡터를 의미합니다.
-
디코더는 c와 이전에 예측된 단어들 {y1 , · · · , yt′ −1 }을 이용하여 yt'를 예측하기 위해 학습됩니다. 그 후에 디코더가 확률을 계산해주빈다.
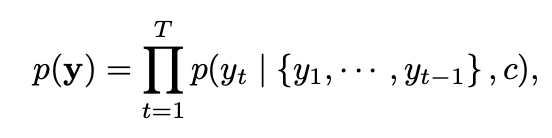

-
여기서 g는 yt의 확률을 나타내주는 nonlinear, multi-layered function이고 st는 RNN의 hidden state를 의미합니다.
Learning to align and translate
3.1 Decoder
p(yi|y1, . . . , yi−1, x) = g(yi−1, si, ci) 식을 통해서 conditional probability를 계산해 줘야 합니다. 총 3가지가 필요한거죠! 첫번째, si는 RNN hidden state를 의미합니다. si =f(si−1,yi−1,ci) 를 통해서 계산해줍니당. 두번째 ci는 (h1 , · · · , hTx )의 annotation입니다. 얘네는 인코더가 input 문장을 매핑할 때 hidden state으로 쓰인 애들입니다. 그래서 hi는 i번째 단어 주변 부분들에 더 많은 영향을 받는 정보를 담고 있습니다. 여기서 ci는 alpha ij와 hj를 이용하여 계산이 됩니다.
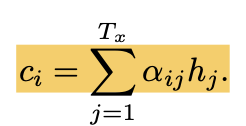
그리고 alpha ij는 아래의 식으로 계산이 됩니다.

: 이런식으로 annotation들의 가중치를 부여한 합과 같은 접근법을 expected annotation을 계산하는 것 이라고도 부릅니다. alpha ij를 타겟 단어 yi가 source word xj에 align될 확률이라고 봅시다. 그럼 ci는 alpha ij를 이용하여 계산된 expected annotation이라고 할 수 있겟죠. 왜냐하면 ci는 alpha ij * hj의 합이니까요. 직관적으로 말하자면, 이는 디코더에서 mechanism of attention 을 실현했다고 볼 수 있습니다. 그렇기 때문에 디코더의 이러한 특성 덕분에 인코더가 모든 문장을 정해진 길이의 벡터로 바꿔야하는 부담을 덜게 됩니다!
3.2 Encoder
인코더는 input sequence x를 읽습니다. encoder에는 BiRNN을 사용하고 있는데, BiRNN은 forward RNN과 backward RNN으로 구성되어 있습니당. forward RNN은 무슨 역할을 할까요? input sequence를 읽어들이고 forward hidden states( ( h 1, · · · , h Tx )를 계산해줍니다. 반대로 backward RNN은 반대 순서로 sequence를 읽어들이고 backward hidden states를 계산해줍니다. 이런식으로 xj주변을 포함하는 annotation hj가 계산되면 이는 디코더에서 사용이 됩니다.
Experiment settings
** 4.1 Dataset **
monolingual corpus(한가지의 언어로 이루어진)이 아니라 parallel corpora data 사용. 모델을 학습시키기 위해서 각 언어마다 가장 많이 이용되는 단어 30000개를 사용하였습니다.
** 4.2 Models **
❓sigle maxout hidden layer
- 기존의 RNN Encoder-Decoder 모델, 이 논문에서 제안한 RNNsearch모델 두가지를 학습.
- 처음엔 30개 단어를 포함한 RNNencdec-30, RNNsearch-30을 두번째엔 50개 단어를 포함한 RNNencdec-50, RNNsearch-50을 사용.
- 각 단어예측에 필요한 conditional probability계산을 위해서 multilayer network with a single maxout hidden layer사용
- SGD 사용
- 제일 근접하게 conditional probability를 최대화 시키기 위해 beam search 사용
Results
5.1 Quantitave results
- BLEU 스코어를 측정해보면 RNNsearch가 RNNencdec의 성능을 훨씬 뛰어넘음.
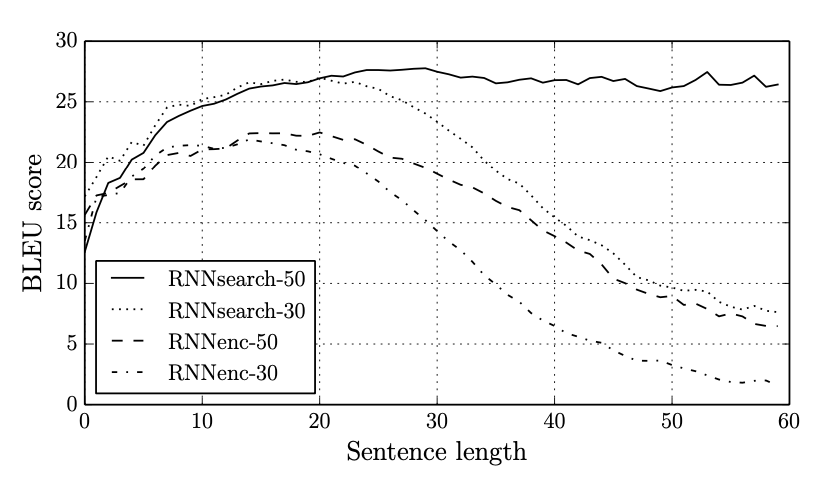
- RNNencdec은 문장의 길이가 길어질수록 성능이 떨어지는 반면, RNNsearch는 괜찮음.
5.2 Qualitative analysis
-
alignment
- 영어와 불어사이의 alignment는 매우 monotonic하다.
- 각각의 matrix의 사선방향이 weight이 제일 큰 것을 확인할 수 있다.
- soft-alignment의 장점? the man을 번역할 때, man에 따라 the의 번역이 굉장히 중요한데 soft alignment는 그것을 가능하게 한다.
-
long sentences
- 이전의 모델보다 긴 문장을 해석하는데에 있어서 확연히 성능이 좋다.
Related Work
6.1 learning to align
handwriting synthesis로부터 제안된 aliging 접근법인데, 다른점은 weight mode 가 한방향으로만 움직인다는 것이다. 하지만 이는 기계 번역에 있어서 굉장히 큰 제한점이라고 한다. 왜냐하면 문법적으로 옳은 문장을 번역하기 위해서는 (long-distance)reordering이 필요하기 때문이다.
이 접근법은 source sentence의 모든 단어에 annotation weight을 계산해준다.
6.2 Neural networks for machine translation
기존에 neural network는 기존의 통계학적 기계에 대한 단일 feature를 제공하거나 후보 번역본들의 리스트를 재랭킹하는데에 사용되었다. 기존에 neural network를 tarket-side language model로써 사용하였는데, 이 논문에서 제안하는 모델은 source sentence에서 바로 번역을 발생시키고 그 자체에서 동작하는 모델이다.
Conclusion
This frees the model from having to encode a whole source sentence into a fixed-length vector, and also lets the model focus only on information relevant to the generation of the next target word.
따라서 RNNsearch는 긴 문장을 번역할 때 굉장히 유용하고 좋은 성능을 냅니다. 앞으로는 unknown , rare 단어들을 더 잘 다루는 것을 해결해야 한다고 합니다.